簡要說明 :
此篇論文發表於2016年,摘要中簡要提出當前人臉偵測與矯正所遇到的困境,例如 : 複雜環境、人臉姿態、光照、遮擋(occlusions)。作者提出一個利用固有的相關關係來提升效能的深度學習框架(Deep Cascaded Multi-task framework),此框架採用一個三階段CNN的聯集架構用於預測人臉與五官在圖像中的位置,並且是一個從粗到細的方法。除此之外,作者還提出一項新的online hard sample mining策略,可以在不需手動採養選取的情況下自動提高效能。
補充與理解 :
針對人臉偵測的應用場景來說,我個人認為作者主要把重心放在場景相對複雜的實時動態人臉偵測。我目前的研究項目與應用場景(門禁系統)中其實是相對簡單,傳統人臉檢測方式(Haar, LBP, dlib)在CPU等級是可以符合大多數的應用,但由於我是用於一般家庭的門禁系統,因此對於在檢測方面魯棒性要求要高,才能滿足用戶體驗,傳統方法嚴重受限於場景。
從摘要中可以得知,作者提出幾個要點 :
- 利用人臉特徵與人臉關鍵點的關聯訊息得到效能與準確度提升。
- 採用三階段輕量的網路聯集架構,每個階段是從粗到細的過程。
- 提出新的online hard sample mining。
網路架構詳解
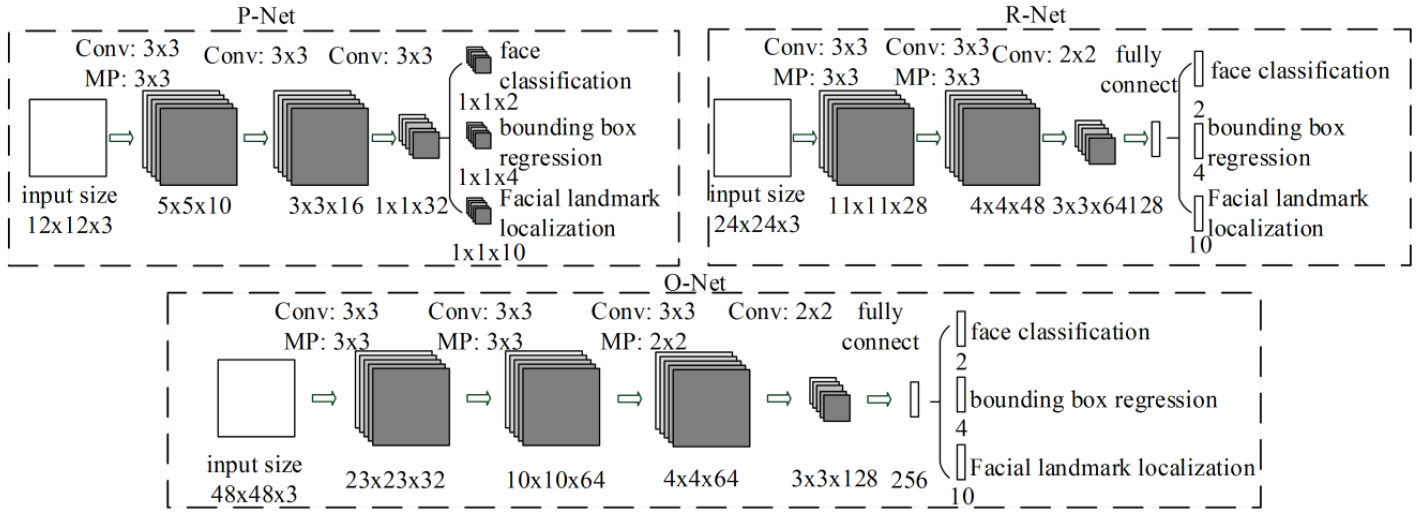
MTCNN的CNN網路結構是參考A Convolutional Neural Network Cascade for Face Detection[1],基於此篇的多重卷積神經網路人臉偵測,MTCNN作者針對上述論文的方法提出幾個缺點 :
- 有些filter缺乏權重的多樣性,可能會限制生產判別的描述。我的理解是filter權重不夠多樣造成產生的判斷不夠準確。
- 與其他多類別目標偵測與分類來說,人臉偵測是一項具挑戰性的二分類任務,因此需要較少數的filter,但需要區別性較較多的filter。
由於上述兩項缺點,MTCNN的作者做了針對性的調整,減少filter的數量,用3x3的filter替換5x5的filter以增加深度而減少計算量,得到更好的效能。與參考的網路相比耗時少,參考下面列表 :
| Group | CNN | 300 Times Forward(s) | Accuracy(%) |
|---|---|---|---|
| Group1 | 12-Net[1] | 0.038 | 94.4 |
| Group1 | P-Net | 0.031 | 94.6 |
| Group2 | 24-Net[1] | 0.738 | 95.1 |
| Group2 | R-Net | 0.458 | 95.4 |
| Group3 | 48-Net[1] | 3.577 | 93.2 |
| Group3 | O-Net | 1.347 | 95.4 |
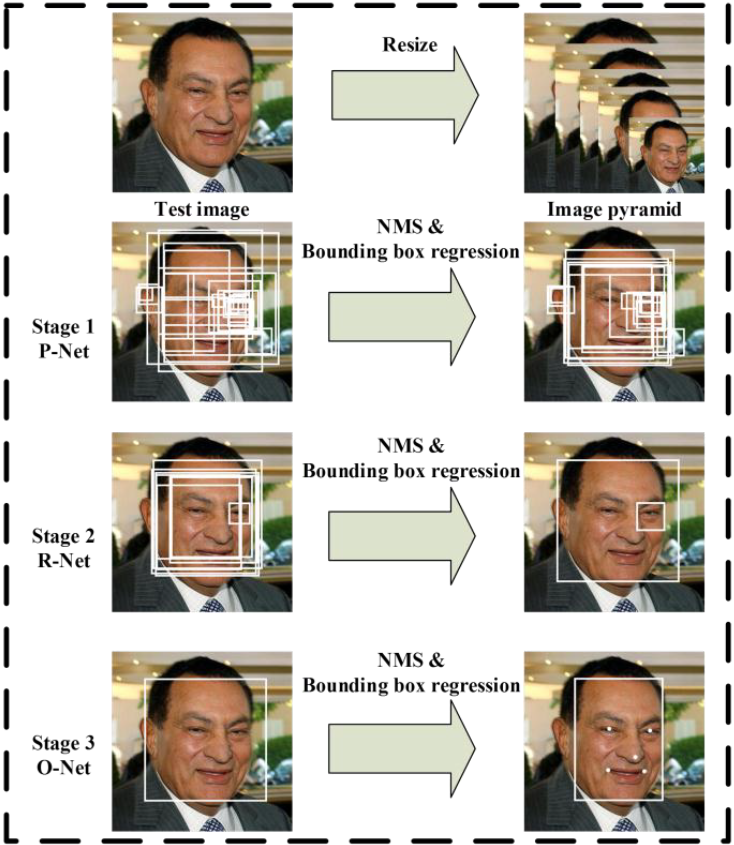
主要分為一項前置作業與三個階段網路 : image > image pyramind、Proposal Network(P-Net)、Refine Network(R-Net)、Output Network(O-Net),其各自的流程為上圖。看似三層網路可能是相連且參數量較多,但實際上各層網路中間還需要經過轉換處理,大致上理解是用bounding box regression vectors去矯正候選框與用NMS(Non-maximum suppresion)融合高重合候選框,其詳細架構為下圖。下列是前置作業和三層CNNs的目的與說明 :
Image Pyramid Stage : 在P-Net收到raw image之前,會先將圖像轉成圖像金字塔(image pyramid),我認為目的是由於訓練時是固定的,所以為了更符合模型,在測試時識別各尺度的人臉準確度提升。缺點是速度降低 : 1. 生成圖像金字塔速度慢 2. 每種尺度(scale)的圖片都需要輸入模型。
圖像金字塔主要是依照原圖給定不同大小的縮放。在MTCNN中圖像金字塔與face minimum size有關 :
1
2
3
4
5
6
7
8
9
10
11
12
13
14factor_count = 0
total_boxes = np.empty((0, 9))
points = []
h = img.shape[0]
w = img.shape[1]
minl = np.amin([h, w])
minl = minl * m
# create image (scale) pyramid
scales = []
while minl >= 12:
scales += [m * np.power(factor, factor_count)]
minl = minl * factor
factor_count += 1Proposal Network(P-Net) : 是一個全卷積網路(fully convolutional neural network),目的是產生候選框與bounding box regression vectors,且方法與Multi-view Face Detection Using Deep Convolutional Neural Network[2]相似。
理解與補充 :
卷積、池化、非線性激勵(激活)都能接受非一致的輸入圖片尺度大小,全連接(fully connection)則是要固定輸入。P-Net在訓練時是固定的輸入大小(12 x 12 x 3),本來在測試時是不需要將輸入的圖片resize,但為了提升準確度,有image pyramid stage。
Refine Network(R-Net) : 是CNN,輸入為P-Net輸出的候選框,目的是剔除錯誤(沒有人臉)的候選框。
Output Network(O-Net) : 與R-Net相似,但主要目的是更清楚描述人臉,會將R-Net輸出的候選框當作輸入,一張人臉會產生一個最後的人臉框座標與五個人臉要點的位置。
訓練任務與損失函數詳解
此網路的目的是實時地得到準確的人臉位置與五個人臉關鍵點。主要利用下述三項任務去訓練偵測器,有無人臉分類器、bounding box regression與人臉關鍵點定位(facial landmark localization)。其中針對不同的任務與分類器,所需要的損失函數也相對不同。以下將針對訓練任務與MTCNN作者所提出的損失函數進行說明與分析 :
人臉分類 :
學習目標被表述為一個二分類問題,任意樣本$x_i$為例,作者使用交叉熵損失(cross-entropy loss) :
$$
L_i^{det} = -(y_i^{det}\log(p_i) + (1 - y_i^{det})(1 - \log(p_i)))
$$其中$p_i$是由網路產生的機率,用來表示一個樣本是一張人臉的機率。$y_i^{det} \in {0, 1}$表示ground-truth 標籤。
理解與疑問 :
針對分類問題,理論上希望錯誤率越低越好,但通常不會直接使用錯誤率作為損失函數,原因是單看錯誤率無法比較模型之間的差異,因為可能出現相同錯誤率但不同準確度的情形。造成在進行模型訓練時難以得到較好的學習方向,當用錯誤率判別時,無法得知目前模型的錯誤是多或是少,因此也不知道最佳模型的要往哪個方向與更新多少。
cross-entropy loss function本身在loss function的兩大類(regression/classification)中屬於分類,且主要用於二分類(Binary)和多分類問題。其中的entropy是接收的所有資訊所包含訊息的平均量,用來察看資料的混亂度與不確定性。softmax激活函數+cross-entropy的含意是真實類別的判斷正確機率,可以得知當cross-entropy越小模型的效果越好(詳細說明1、詳細說明2)。
近年在CNNs中較常見的Softmax loss也就是基於softmax激活函數+cross-entropy與其變形。
Bounding box regression :
作者預測任意候選框與其最近的ground truth之間的位移,學習目標被表述為一個回歸問題,且對任意樣本$x_i$使用歐式損失(Euclidean loss) :
$$
L_i^{box} = ||\hat{y}_i^{box} - y_i^{box}||_2^2
$$
其中$\hat{y}_i^{box}$回歸目標是從網路獲取的,且$y_i^{box}$是ground-truth的座標。總共有四個座標,包含左上、寬、高等等,且其限制用數學式表示為$y_i^{box}\in\mathbb{R}^4$,$\mathbb{R}$的意思是實數。理解與疑問 :
$\lvert\lvert{x}\rvert\rvert_2$代表的是第二正規化/范式,單純將上述的公式轉換後發現與L2公式相同,但歐式損失定義為$\frac{1}{2N}\sum_{i=1}^N\lvert\lvert{x_i^1-x_i^2}\rvert\rvert_2^2$,可以發現與上述的公式比多了$\frac{1}{2N}$,所以在這裡我有一些困惑。除此之外,還有在此用歐式損失的涵義為何目前我也沒理解。
人臉關鍵點定位 (facial landmark localization) :
與bounding box regression任務相似,人臉關鍵點偵測(facial landmark detection)被表述為一個回歸問題,且作者最小化了歐式損失(Euclidean loss) :
$$
L_i^{landmark} = ||\hat{y}_i^{landmark} - y_i^{landmark}||_2^2
$$其中$\hat{y}_i^{landmark}$是從網路獲取的人臉關鍵點座標,$y_i^{landmark}$則是ground-truth座標。總共有五個人臉關鍵點,包含雙眼、鼻子與左右嘴角,且$y_i^{box}\in\mathbb{R}^{10}$。
理解與疑問 :
由於與bounding box regression運作相似,因此也是使用了歐式損失,作者在文中說針對此部分的損失函數做了最小化。
Multi-source training :
將不同任務分配到每個CNNs中,造就在學習的過程中需要不同類型的訓練圖片,例如 : 包含人臉的、不包含人臉的與部分矯正(對齊)的人臉圖片。在某些情況下,上述的損失函數可能不會全部都用到,例如 : 圖片背景區域樣本只計算$L_i^{det}$,另外兩個損失函數的數值被設定為0。此任務可以直接用一個sample type indicator實現,所有的學習目標可以被表示為 :
$$
\min \sum_{i=1}^N{ \sum_{ j\in{det,box,landmark} } {\alpha_j\beta_i^jL_i^j} }
$$其中$N$是訓練樣本的數量,$\alpha_j$表示任務的重要性。作者為了得到精度更高的人臉關鍵點定位,在P-Net與R-Net中用的參數為$(\alpha_{det}=1,\alpha_{box}=0.5,\alpha_{landmark}=0.5)$,O-Net為$(\alpha_{det}=1,\alpha_{box}=0.5,\alpha_{landmark}=1)$。$\beta_i^j\in{0,1}$則是此樣本類型指示器 ($\beta_i^j\in{0,1}$ is the sample type indicator),在此條件下用隨機梯度下降(stochastic gradient descent)訓練CNNs是很自然的。
理解與疑問 :
作者將上述三項損失函數統整到一項數學式中,但我對multi-source training的概念有幾項不了解的地方 :
- 什麼是sample type indicator,還有其作用是什麼?
- 如何把前三項損失函數統整成一項數學式?
- 為什麼在這樣的條件下使用隨機梯度下降是很自然的? 是否有反向傳播?
Online Hard sample mining :
與最初的分類器在被訓練後進行traditional hard sample mining不同,人臉分類任務中採用online hard sample mining用來適應訓練過程。
在每個mini-batch的前向傳播(forward propagation)階段中,依照已經計算完成的損失函數數值排序全部樣本,並選擇前70%作為重樣本(hard samples)。在反向傳播(backward propagation / backpropagation)階段只從重樣本中計算梯度(gradient),這代表忽略簡單的樣本,換句話說,就是忽略在訓練中對強化此檢測器幫助較少的樣本。
理解與疑問 :
我理解在此論文中提出的人臉檢測方法中使用online hard sample mining取代traditional hard sample mining,目的是忽略training中對提升檢測器精準度幫助較少的樣本,如此一來,既可以維持準確度亦可以提升速度。
優化方向
我認為優化不需要只考慮網路本身,可以分成幾個方向來剖析問題 :
input :
- 原圖resize : 對input做下採樣。說白一點,有點像是slide window在掃描圖片時,圖片縮小造成需要掃描的面積減掃,導致運行速度加快,準確度下降。如何找到平衡點需要programmer自行調適。
- face minimum size : 放大掃描人臉的最小框。當一張圖片上用slide window(face window)掃描原圖生成候選框時,框體面積增大而掃描面積固定導致速度會提升,但人臉小於基本框體則無法偵測出來。
網路 : 目前針對網路的部分只有一些想法,主要是此篇論文為2016年提出,在之後提出的方法與改念都可以用在優化的部分。目前可以分稱幾個部分 : 卷積、網路架構、池化、損失函數、image pyramid stage。
output : output的部分其實有牽涉到網路結構,雖然是改進網路結構,但主要的思想來自我認為不需要O-Net輸出的facial landmark,而facial landmark確實對人臉偵測有所幫助,因此想切除O-Net只做P-Net與R-Net。目前的結果不甚理想,不知道原因為何,速度在face minimum size = 20下只提升1~2fps且準確度略有下降。
框架 : 可以替換或是增加Caffe等框架,例如 : 用OpenCV的dnn、騰訊的ncnn、小米的MACE、Intel的OpenVINO或是Qualcomm的SNPE等等,以上大多是移動平台對自家硬體提出的加速框架,而其中NVIDIA也有提出基於自家GPU的加速框架TensorRT。但要特別注意每個框架支援那些其他的參數與模型檔案。
Source Code
下列所提出的source code我都有實際跑通與測試,我使用的環境是 : Ubuntu 14.04 64-bit, CPU i5-4590 , Memory 16G, GPU GTX 960。
除了原作是Caffe + MatLab之外,其餘都是Tensorflow + Python,在某篇Blog(找到此篇Blog將附上連結)中提到,好像用Tensorflow框架實現會比用Caffe框架更高效。
- 論文github : 是由論文的原作親自實現並開源的程式碼,且有兩個版本,我還未比較兩版本的差異。
- davidsandberg/github : 這個版本的MTCNN是Python + Tensorflow,也是最多人參考並實現的MTCNN版本,其目的是做FaceNet(人臉辨識)之前的人臉檢測。
- wangbm/github : 這個版本是基於davidsandberg與原作實現的,有提供完整的網路架構、train與test的腳本,是我目前更動最多的版本。
- AITTSMD/github : 此版本是基於Tensorflow中最多人使用的source code之一,作者是中國人,所以在github的issue中提問可以用中文,作者也會用中文回答你。
- ipazc/github : 這份程式碼的作者將程式封裝,對Python的使用者來說,可以直接在terminal中下
pip install mtcnn來安裝,並直接在python中import mtcnn來使用。對單純想使用此演算法的人而言相當方便,但如果你想跟我一樣針對網路做優化或是修改,那就完全不能使用這個版本。